Dev'Obs #13 - CI/CD
Durée: 76m10s
Date de sortie: 05/05/2019
Intégration et Déploiement Continue
C'est d'abord une culture. Quand on est en DevOps, on prend tout le monde.
DevOps et agile font effectivement partie de la même famille.
Sa virtualisation applicative, c'est très bien.
Aujourd'hui, ça nous prend 10 minutes et un café.
Ce n'est ni être dev, ni être DevOps. C'est avant toute la communication.
Ce mouvement DevOps, c'est tout simplement drivé par la communauté
et endorsé par les entreprises.
J'ai adopté une démarche DevOps.
Le développement agile, on a accéléré des poignements.
Ça amène une clarté sur le travail de l'Ottawa.
Être dans une démarche d'amélioration continue.
On retrouve face à des savouilles naturelles ensemble.
Ça donne des résultats contrées.
DevOps.
L'objectif individuel, ça s'atteint alors qu'une ambition, ça se partage.
Bonjour à tous et à toutes.
Bienvenue au 13e numéro de DevOps.
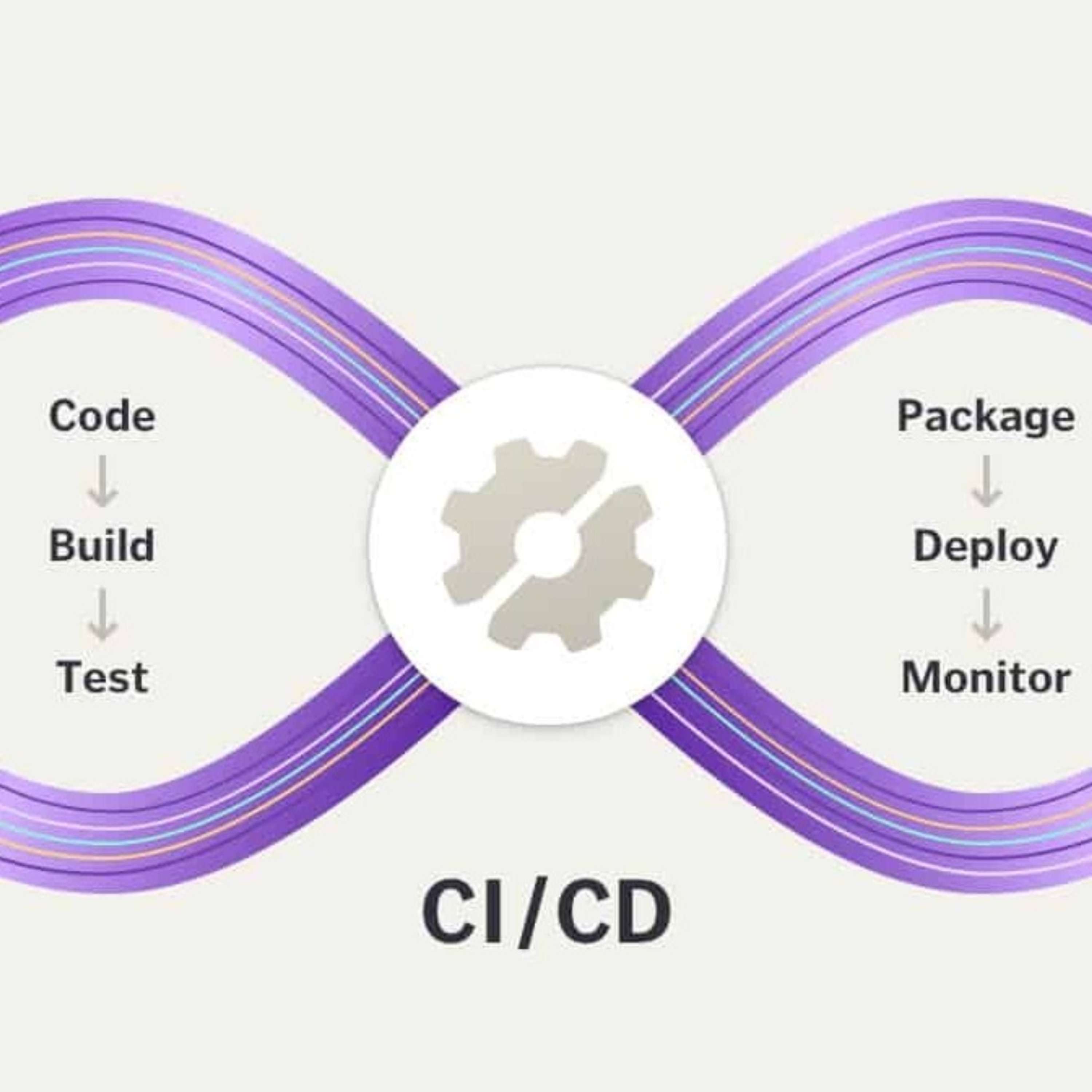
Aujourd'hui, nous allons parler de CI-CD.
Très vite, CI-CD.
C'est pour Continuous Integration, Continuous Deployment et Delivery.
Les deux.
Et on en parlera.
C'est un peu teasing pour la suite.
Nous sommes encore en direct sur YouTube.
Désolé pour le petit retard d'ailleurs.
Et autour de la table, nous sommes quatre.
Et nous avons même quelqu'un en remote.
Cette fois-là, on est encore en train d'expérimenter quelque chose.
On va voir si ça marche.
Et d'ailleurs, on va te laisser de présenter.
Oui, bonjour. C'est Christophe.
Oui, un peu absent.
Moi, c'est Christophe. Je suis parti du collectif de freelance Lydra.
Et je suis aussi animateur des compagnons du DevOps.
Super.
Est-ce qu'on lui fait le petit rituel pour toi, c'est quoi le DevOps ?
On me fait après ?
Tiens, vas-y, présente-toi.
Bonjour, Victor.
Un des co-créateurs du podcast.
Et participe en récurrent.
J'ai été à la dernière fois aussi.
Depuis, j'ai changé de boîte.
J'avais fait un petit teasing la dernière fois.
Je suis maintenant dans une boîte qui s'appelle Agorize.
Et qui fait une plateforme de création et d'animation de challenge d'innovation.
Je ne vais pas trop rentrer dans le détail, parce que ce n'est pas le but.
Allez sur le site web, c'est ça ?
Allez sur le site web Agorize.com.
Pup.
Super.
Moi, c'est Romain Soufflé.
Ça fait plusieurs fois que je viens sur DevOps.
J'aime bien ça.
Du coup, je reviens.
Et moi, par contre, j'ai arrêté de me vendre comme DevOps,
parce que je trouvais ça trop confus pour les clients.
Du coup, je dis que je m'occupe des problèmes de déploiement
et de tout ce que ça peut comporter.
Voilà.
Ok.
Bonsoir.
Moi, c'est Xavier.
Et je travaille encore chez Leboncoin.
Ah, c'est en live.
En merde.
Voilà.
Je suis assez heureux chez Leboncoin pour l'équipe d'Athane Engineering.
Ok.
Il y a un peu de teasing.
Et donc, moi, Guillaume Le Tron.
Et je suis freelance.
Je ne pourrais pas dire non plus sur quoi,
mais bon, je bosse pas mal sur Cube.
C'est sur Cube.
Voilà.
Bon, pas trop non, je bosse sur Cube.
Globalement.
Mais bon, vous avez plus d'infos
quand à chaque fois qu'on fait des dentons cubes.
Donc, si jamais vous ne le connaissez pas,
vous pouvez aller voir les dentons cubes
qui sont des podcasts spécialement sur Cube.
C'est toute son actualité et tout ce qu'on peut faire avec.
Des choses très bien.
Mais là, aujourd'hui, on va parler de la CI CD.
Donc, on a un peu dit CI pour Continuous Integration.
Je suis allé chercher la définition de Wikipedia
parce que ça me paraît toujours bien d'avoir les bases comme ça.
Donc, l'intégration continue est un ensemble de pratiques
utilisées en génie logiciel
constituant à vérifier
à chaque modification de code
que le résultat des modifications
ne produit pas de régression dans l'application développée.
Le concept a été pour la première fois mentionné par Gradibosh,
bouche, je sais pas, bouche en ma vie,
et se réfère généralement à la pratique de l'extrême programmier.
Le principal but de cette pratique
est de détecter les problèmes d'intégration au plus tôt,
lors du développement.
De plus, elle permet d'automatiser l'exécution des suites de test
et de voir l'évolution du développement du logiciel.
Sachant que je suis allé voir,
cette définition-là a été faite en gradibush en 1991.
Donc, on voit que c'est quelque chose qui n'est pas du tout récent.
À l'échelle technologique, oui.
En tout cas, dans sa conceptualisation.
Par contre, clairement dans l'application,
on est dans quelque chose qui date des dix dernières années,
on va dire peut-être un peu plus qu'un de ces dernières années.
Donc, voilà déjà pour la CIA.
Et la CIDI dont on va parler, c'est donc pour Continues Deployment,
Continues Delivery.
C'est la livraison continue.
La livraison continue est une approche d'ingénierie logicielle
dans laquelle des équipes produisent des logiciels dans des cycles courts,
ce qui permet de le mettre à disposition à n'importe quel moment.
Le but est de construire, tester et diffuser un logiciel plus rapidement.
Donc voilà, on a à peu près les deux étapes CIA-CIDI.
D'abord, j'aimerais vous demander un peu à tous
quel est pour vous votre première expérience avec la CIA et la CIDI.
Donc, je ne sais pas, Tiens, Christophe, comme tu es en remote.
En remote, c'est toi qui va commencer.
Moi, la CIA, ma première expérience,
j'ai une fille, il y a quelques années.
C'était même plutôt de la CIDI à l'époque.
Je ne m'occupe pas de la CIA.
Plus récemment, j'ai découvert ça avec les devs.
J'ai commencé à bosser dans le web pas trop tard.
Donc, ils m'ont montré ça.
Et puis, comme j'étais passionné du déploiement,
j'ai tout de suite pris le pas de la CIA et de la CIDI.
Et autour de la table, est-ce que vous avez...
Alors, moi, ça va être un peu cocasse.
Mais la première expérience que j'ai avec le déploiement,
c'est de me connecter sur une machine et faire un guide pool.
Je dois avouer que c'était pas terrible.
Et en parallèle de ça, la première expérience que j'ai eue,
elle était un peu luxueuse,
puisque c'était à côté de cette entreprise
où je faisais un peu de contribution sur OpenStack.
Et là, pour le coup, ils avaient un process
qui était vraiment blindé de chez blindé.
Et pour tout à vous, j'en ai jamais retrouvé
des aussi bien foutus,
enfin, aussi complets, je ne vais pas dire bien foutus,
je veux dire complets,
dans les entreprises que j'ai traversées,
même si j'ai essayé de mettre en place des choses.
Donc, c'est un peu étrange mon premier contact avec la CI-CD.
Je n'arrive pas à savoir si c'est plutôt le fait de le faire manuellement
dans la toute première boîte,
ou si je ne peux pas parler de CI-CD à cette époque-là
et que ça commence avec OpenStack.
Je n'arrive pas à savoir c'est quoi
ma première expérience de CI-CD.
Ouais, moi, c'est un peu comme mon premier expérience
d'intégration, de déploiement, c'est très, très manuel.
Je ne sais pas si on peut dire un peu comme tout le monde ici.
Probablement, oui.
Mon premier vrai contact avec la CI,
je pense que c'était,
à mon avis, c'était chécrit et haut, je pense.
Parce que dans les boîtes où j'étais avant,
c'était une toute petite boîte
et on n'avait pas vraiment de process en place.
Et ouais, c'était déjà un truc qui était assez industrialisé.
Donc, c'était quand même...
Ça valait ce que ça valait,
mais c'était quand même plutôt carré, on va dire.
En ce qui me concerne,
ma première expérience en termes de CI-CD,
je crois que je l'ai rencontrée lors d'une mission
chez Figuaro Classifieds.
Et pour le coup, c'était plutôt assez bien huile.
C'est-à-dire qu'ils avaient déjà atteint une certaine maturité
avec une interface en clic button
pour déployer depuis du ESVN et d'autres choses et des tests.
Et sinon, c'était en parallèle également chez Smile
avec ce qu'on disait à l'époque, les PICs,
les plateformes d'intégration continu,
avant que CI devienne vraiment à la mode.
En fait, oui, c'était juste une traduction française.
D'ailleurs, moi en fait, à la base,
de la base, mon première expérience avec Sash,
c'était que j'étais vendeur de PIC,
c'est-à-dire que j'avais développé toute une suite de Tooling,
notamment autour de PHP.
Pour le coup, c'était une plateforme d'intégration
qui m'aillait du Jane Keane, du Rennmind,
des tests unitest pour PHP, etc.
Pour vous dire, c'était en 2009,
il fallait que j'explique aux gens,
moi qui n'en avais, qui n'était pas du tout développeur,
il fallait que j'explique aux développeurs
ce qui était un test immunitaire.
J'étais là pour leur dire quelles sont les tests unitaires,
quelles sont les tests les ligniteurs,
en fait, à l'époque, il faut voir qu'un ligniteur,
il y avait très très peu de gens qui en avaient déjà utilisé.
En fait, ma première expérience de boîte,
et vraiment, c'est ma première expérience de boulot,
c'était de vendre de l'intégration continue.
En fait, j'ai baigné dedans dès le début,
c'est un peu une expérience un peu particulière,
je pense, par rapport à...
Intégrateur d'intégration ?
C'est ça, exactement.
C'était un peu particulier.
Donc voilà, dès le début, j'ai baigné dedans,
et après, quand je suis allé faire autre chose que du conseil,
mais directement dans des entreprises,
pour le coup, j'ai continué là-dessus.
C'est pour ça que...
Je ne sais pas si je l'ai déjà dit,
mais pour moi, le lien avec le DevOps,
ça a été le fait qu'un jour, mon CTO
m'a donné un lien en disant,
« Regarde, ça ressemble beaucoup à ton métier,
et ça s'appelle DevOps.
Et du jour au lendemain, je suis passé
d'intégrateur système ou alors d'administrateur système,
je suis passé à DevOps.
Mais en fait, vraiment,
c'était déjà ce que je faisais avant.
Faisais déjà sans avoir un terme ?
Sans avoir un terme,
à mettre tout dessus.
Ce qui était vraiment très particulier.
Donc voilà un peu mon lien, en tout cas,
avec la CI-CD.
D'ailleurs, je vais aller...
Je pense qu'on en reparlera au moment
où on parlera de la CEDI,
mais on le met toujours dans cet ordre-là,
et je pense que nous tous autour de la table,
on va d'abord faire de la CI-CD
avant de faire de la CEDI.
Si jamais un jour on a fait de la CEDI.
Donc voilà.
Et là, en fait,
on a parlé très généralement
de ce que c'était que la CI et la CEDI,
plus en rentrant dans les détails,
parce que là, j'aimerais bien
dans une petite partie un peu technique l'un de dans,
quelles sont les plateformes
que vous vraiment vous utilisez,
que vous avez utilisées,
pour qu'on ait un peu votre bas-grande technique là-dessus.
Alors, moi je vais commencer.
Je pense qu'un peu par-mals d'entre nous,
j'ai découvert au début
l'intégration continue avec Jenkins.
Jenkins, tout le monde le connaît,
tout le monde le déteste, pourtant tout le monde l'utilise.
Et ensuite, j'ai pu aussi découvrir des outils
comme Travis.
Et là par contre, c'est un peu le rêve,
avec un concept repository driven,
qu'on pourra peut-être voir en détail plus tard,
mais Travis, ça a vraiment été pour moi
l'avènement de la CI undimend.
Puis ensuite, les dérivés comme drone,
comme GitLab avec son GitLab CI,
et ce genre de choses.
Est-ce que vous en avez vu d'autre, vous ?
Oui, comme vous avez,
j'ai découvert d'abord, surtout avec Jenkins,
que pas mal de bottes utilisées et utilisent toujours.
C'est encore très largement répandu, je pense.
Dans ma boîte actuelle,
c'est du Circle.
C'est mon premier contact avec Circle,
donc ça fait que trois semaines que je suis dessus,
j'ai pas encore vraiment trop mis les mains dedans.
D'ailleurs, je pense que je vais devoir
mettre un peu les mains dedans, parce que
mon avis est de l'optimisation à faire.
Ils ne sont pas du tout dans la paralysation
des tests et des jobs, et du coup, c'est un peu un enfer.
Ça met une éternité à la bulle, mais je pense que c'est plus un problème
d'utilisation que d'outils, à mon avis.
Donc je vous en dirais plus, peut-être la prochaine fois,
en appartez.
Mais Circle, Jenkins,
j'ai déjà vu du Travis aussi, etc.
Et Christophe,
toi, est-ce que je vois même que tu nous as parlé
même de Code Chip ?
Très intéressé, et naïvement,
c'était un peu mon premier.
Et après, j'ai du Circle CIA
et du GitLab CIA,
et là, je décroche pas
de GitLab CIA depuis que je l'ai découvert.
D'accord.
Mais justement, je pense, enfin moi,
je n'ai pas grand-chose à rajouter, je ne sais pas.
Moi, à la limite, je peux parler de cette première expérience
que j'ai eu d'une CIA où je l'ai bricolé
moi et les mémines, mais c'était du bâche,
et je préfère pas en parler, finalement.
Je n'ai pas su honte de le dire.
C'est assez bien. On voit que tous dans notre cheminement,
on est passé par Jenkins.
Alors si jamais on devait faire des catégories
là-dessus,
qu'est-ce qui différencie, selon vous,
un Jenkins
de tout ce dont on a parlé, d'un Circle CIA, etc.
et même après, d'un GitLab CIA.
Quelles sont pour vous ces différences
qu'on pourrait faire ?
Pourquoi vous dites qu'on a commencé avec Jenkins ?
C'est pourquoi on n'y est plus maintenant, en fait.
En fait,
moi, je pense que
justement, je vais faire le lien avec la toute première expérience
que j'ai eu, en fait, où on faisait ça avec du bâche.
En fait, on a fait des scripts
pour juste lancer plusieurs commandes
de l'une à l'autre et faire notre intégration
manuellement.
Au final, Jenkins,
on l'a vraiment considéré pour ce que c'est.
Il lance des jobs, en fait. Il fait des process
qu'on lui demande de lancer.
Donc, pour faire ça,
c'est très bien de...
On peut le faire avec des scripts bâches,
comme on veut, avec un cron job. En final, ça marche.
C'est juste que c'est pas maintenable.
Et l'avantage
de ces outils, c'est qu'ils proposent quand même pas mal d'options
telles que, dans le cas
de Jenkins file.
Travis, on apparaît un Travis YAML
qui nous permet de faire des choses.
On va avoir
des options qui vont permettre de nous faire de l'ordonnancement
après un commit
ou
de lancer à une certaine heure.
Ça va être ce genre d'options, je pense,
qui vont différer d'une plateforme à l'autre
et qui vont nous permettre de choisir vraiment notre outil
et de savoir à quel point
il peut s'intégrer avec le workflow de notre équipe
ou de l'entreprise, en fait.
Et l'idée que tout le monde
est quitté Jenkins, c'est surtout que l'outil
quand même un peu vieillissant et que les options
qui proposent sont globalement
soit assez basiques, soit il faut passer par des dizaines
de plugins qui, eux, risquent de planter.
Et, pour en près, j'ai plein d'autres raisons en tête,
mais c'est parce que personnellement, je n'aime pas Jenkins
et donc je préfère éviter de troller
enfin, on vient de commencer.
Je vais pas faire ça maintenant.
Si, si, tu peux y aller.
En fait, enfin, là, si jamais, moi en tout cas,
je devais faire une distinction.
En fait, on a vraiment, oui, Jenkins
qui est une sorte de runner,
tu as parlé de CronJob, tu as parlé de Nutsa.
On a vraiment une sorte de runner
de script à la voler, en fait.
On a vraiment une sorte de runner
on définit dans un endroit, bon, bah voilà,
quand tu viens de commit, on a des systèmes d'event,
des choses comme ça, mais voilà, tu vas exécuter
tel script, etc.
Et en fait, juste, on a, on a pas,
enfin, on a juste pas à le coder dans un CronJob, etc.
On a quelque chose d'un peu plus distribué et encore.
Jenkins, surtout, ça avait une web UI.
C'était ça qui était intéressant.
C'est que c'était accessible ou très vite,
en fait, tu spawnes ton jar, ton war, pardon,
ton war, tu as une UI, tu peux commencer à coder
tes trucs avec très rapidement, voilà,
je veux check outer mon code de tel endroit,
j'exécuter tel script et puis,
il pouvait watcher.
Donc, c'était l'un des avantages de Jenkins,
c'est que très vite, tu pouvais faire des trucs.
Par contre, l'inconvénient, c'est que
avec tout son ecosystem,
son immense flexibilité,
parce que tu as a watnit plugin ou un truc,
ça commençait à être un clic au drôme
et ça commençait également à être un truc
qui n'était pas manager,
comme le reste de ce qu'on essaie de faire
avec l'infrastructure et les configs.
C'était un truc énorme qui était imbacupable,
inversionnable.
Les derniers problèmes que j'ai eu avec Jenkins,
c'est qu'il était impossible à reconstruire
depuis le code source.
Donc, en fait, on était obligés de faire du clic au drôme
pour le reconfigurer et donc,
on ne pouvait pas se passer de la VM
qui contenait Jenkins, on ne pouvait pas la supprimer
et la recréer et ça,
ça a été un vrai problème
dans mes expériences passées.
Et donc justement, vous avez évoqué
les problèmes de Jenkins,
comment les outils
qu'on a dit maintenant qu'on utilise
ont réussi à résoudre un peu ce problème.
Christophe, tu me parlais notamment
que tu utilisais maintenant GitLab CI,
mais même avant ça,
quel pour toi le changement
ce qui fait que tu vas aimer un outil
plutôt que Jenkins peut-être ?
Alors déjà, j'ai beaucoup souffert avec Jenkins
aussi, avec sa gestion des workspace
et du fait qu'on érite des workspace passés
et donc déjà, on ne pouvait pas passer
si il était mal nettoyé,
on pouvait être
autre chose qui était.
Du coup, avec les nouvelles plateformes
CodeChip et
l'avantage c'est qu'on
avec
si on veut récupérer des choses
c'est à nous de garder entre chaque globe
et du fait, c'est quand même beaucoup...
J'ai l'impression qu'on me perd un peu Christophe.
Je crois qu'on a loupé des mots
de ce que tu viens de dire.
C'est vrai que c'est parti
Jenkins, le fait que
les jobs soient distribués
et le workspace pas du tout
pas du tout
t'as Tomy qui en fait tout le monde partage
un peu le même espace, les mêmes machines, les mêmes runners.
Au final, de ce que je vois
en tout cas, il y a un point important
c'est que justement, voilà, on a ce single runner
et on a aussi le fait
qu'on a une définition
YAML, c'est à dire que là
tu parles tout à l'heure d'infrastructure AsCode
etc. On n'en aurait très bien pu
et d'ailleurs on l'a déjà vu
des gens utiliser de l'infrastructure AsCode
pour configurer du Jenkins.
Je ne vous prendrai pas du doigt mais je me souviens
de gros chefs dégueulasses
pour
auto-configurer des Jenkins.
Et justement, la différence qu'on a maintenant
en fait, on a résolu le problème
encore une fois et comme toujours
dans la génierie en reportant le problème ailleurs
et heureusement
c'est que en mettant les YAML
au sein des répositories
ça veut dire qu'on peut avoir même plusieurs CIA
qui tournent sur un même code
en fait.
Je pense que tu marques un point sur ce que tu viens de dire
tu soulèves un point intéressant
c'est que justement, la définition
des jobs est à côté de ton code
elle est avec ton code en fait.
C'est repository de river.
Donc tu peux lire ton code et en même temps
voir comment il est buildé, comment il est déployé
comment machin.
Et c'est vachement plus simple
que d'aller voir des
job Jenkins qui sont configurés dans
tu sais pas où, qui font, tu sais pas quoi
qui sont impossible de reproduire.
Et là en plus c'est vachement plus simple.
Ça me fait penser à ces entreprises qui essayent
d'embaucher des gens pour juste faire la CIA CD
et ensuite la donner au dev
sauf que ça marche pas en fait
puisque chaque projet est buildé à sa manière
avec ses spécificités
et du coup le process de build
doit venir de l'équipe de dev
et personne ne peut donner une CIA
et la proposer à l'équipe de dev
et que espérer que l'équipe de dev
s'en servent comme si c'était la leur
et ça rejoint
ce côté où en fait on définit les pipeline
on définit nos scripts, nos process
dans le repository. Les devs
ont la main dessus et c'est les devs qui contrôlent
au final le build de leur produit
dans la CIA.
Et justement ça me permet de rebondir
depuis tout à l'heure
on parle de CIA, on parle de tests
mais en gros, qu'est-ce qu'on fait
dans une CIA ? Globalement,
quelles sont les actions
que vous avez besoin de faire dans une CIA ?
C'est les tests.
Alors quel test ?
C'est quoi pour ton test ?
Test unitaire.
Éventuellement, test d'intégration.
C'est tout ce que tu vas voir la plupart du temps.
Test unitaire, test d'intégration, build de ton artifact
à la fin.
Oui justement,
dans ma mission actuelle
on a justement pour mission de popper
des CIA pour chaque projet
et du coup on a dû proposer une définition
qui plaisait un peu à tout le monde
pour que chacun puisse comprendre
un peu ce qu'on fait. Donc nous la définition qu'on a proposée
c'était la CIA, au final le but de la CIA
c'était de proposer un package déployable
ce qui doit sortir de la CIA
nous on peut le récupérer
côté déploiement pour le déployer
et donc définir le package déployable
du coup ça c'est un vrai problème
et en général on donne l'adresse
des 12 factor app
comme définition d'un package déployable
et je sais pas
s'il faut que je définisse 12 factor app
vu qu'on en parle régulièrement.
Mais vas-y, oui, enfin
pour ceux qui nous rejoignent.
Bon, alors j'ai ouvert le lien
parce que je ne les connais pas tous par coeur.
Il a préparé.
Oui, enfin j'ai préparé à moitié.
Donc les applications 12 factor
c'est
un document
au final qui est disponible sur internet
qui se fait en douche chapitre
et il vise à expliquer
les bonnes pratiques
comment écrire une application pour qu'elle soit
cloud ready et qu'on puisse
l'exploiter correctement
et donc dans les
différents chapitres on peut trouver
par exemple la phase
build release run
donc comment on va séparer
les différentes étapes
du cycle de vie de l'application
comment on va gérer les processus
comment on gère
les logs
voilà c'est...
En fait en fait c'est la définition
à l'époque ce qu'on appelait les cloud ready application
c'est-à-dire comment on fait
en sorte pour que son application devienne
cloud ready. J'aimais bien ce terme
cloud ready c'est plutôt pas mal
On dit cloud native maintenant
Non c'est pas tout à fait pareil
C'est cloud ready
c'était comment on arrive
à faire passer son application
Il y avait aussi un côté un peu transition
qui était...
Mais voilà on avait cette idée
donc là on a parlé
c'est assez bien en fait
de la fin de la CIA, tu définis la CIA
par sa fin
En fait nous c'est comme ça qu'on le définit le mieux
parce qu'on veut laisser la liberté totale
au dev et au projet
En fait il faut bien comprendre qu'il y a pas quelqu'un
qui va créer la CIA pour un projet
et vraiment le projet doit venir s'incapparaître
ce process de build
il doit le faire lui-même
on pourra pas l'inventer pour lui
du coup la seule chose qu'on dit
c'est...
voilà ce que vous devez nous livrer à la fin
et après on peut vous aider à le faire
si jamais vous avez besoin d'aide
mais livrez-nous un paquet de déployables
et c'est aussi parce que dans ma mission actuelle
nous n'avons pas la main
sur les différentes CIA qu'on la définit de cette manière là
j'aime bien cette définition
où tu dis voilà le contrat
on veut ça à la fin entre deux
faites comme vous voulez du moment que ça marche
et pour vous et pour nous
pas de problème
depuis tout à l'heure on parle l'application
mais c'est dans qu'on fait
les tests etc unitaire
pour la plupart des projets c'est possible
tes intégrations extens
mais par exemple quand on parle d'un
JIS sur JIS type réact
etc
moi personnellement en tout cas
la façon de tester j'en ai aucune idée
et d'ailleurs elle est très très différente
enfin un test d'intégration c'est quoi
on se pone un navigateur en utilise du selenium
etc
si jamais je fais mon application en go
typiquement je vais pas du tout spawner un selenium
donc c'est pour me montrer
un peu la volatilité qu'on peut avoir
dans les différents systèmes
entre les façons de tester
en fait un projet ne sera pas du tout
du tout tester comme un autre
et intégrer comme un autre
et il faudra peut-être un outil H
complètement différent en final pour le tester
tu dis selenium tu dis machin
peut-être que tu pourras pas le faire avec
je sais pas du geek lab
mais avec du geek lab il te faudra un autre outil
pour spawner tes navigateurs
par exemple une application mobile
comment on fait pour faire des tests intégrations
sur un apk android
c'est voilà et pourtant
c'est des choses mais en fait
là il y a une réponse qu'on n'a pas tout à fait eu
je trouve que c'est
pourquoi on fait de la CIA
genre le
qu'est-ce que van savane nous apportait
concrètement
pourquoi on a mis en place ce genre de choses
moi je peux très bien développer
pousser mon code ça part en prod
en fait je pense que
au début
avant qu'on arrive à la définition de romain
avec un livrable
qui est un certain format
c'était essentiellement des tests
exécutés en fait la continuation
intégration c'était de se dire ok
j'ai fait des changements
soit sur une branche ou autre chose
qui doivent être maintenant intégrés dans la codebase commune
et je voudrais vérifier
que ce que j'ai fait
ce que j'ai introduit comme changement
n'a pas cassé le reste de logiciel
et en théorie ça exécutait d'abord des scripts
et souvent
la construction de ton artefact
il arrive en déploy step
c'est à la fin quand une fois que tous les tests sont verts
c'est à dire mes tests de lintes
mes tests de mes unites test
ou mes tests fonctionnels un peu plus haut niveau
une fois que les tests applicatifs sont verts
je package mon application
pour du déploiement et en fait
il y a des soft comme GitLab
enfin je vais pas les citer
comme ça pour les pointer du doigt mais
qui propose
une solution en fait tout en un CICD
alors que pour moi
c'est quand même deux types de workflow
qui sont différents
mais qui ne doivent pas se parler
et être conscients de l'un et de l'autre
mais c'est quand même deux steps un peu différents
d'un côté je fais de l'intégration continue
je vérifie juste que mon code fonctionne
et je ship de l'artefact
et d'un autre côté je vais faire du déploiement
en choisissant un artefact et en le faisant valider
stage by stage
jusqu'à la production
c'est assez marrant en fait c'est la définition
que je comptais à un moment à arriver
parce que c'est vrai que ça c'est un peu que j'ai
et c'est marrant, enfin là autour de la table
on est peut-être dans un microco
c'est un peu trop...
un peu trop fermé, on se connaît un peu trop
en avis
c'est pas du tout une définition standard
toi Christophe qui est pour le coup
nouvelle arrivant l'un de l'autre
est-ce que toi tu avais déjà
cette décomposition entre
CI par artefact
et CD
vraiment le déploiement de cet artefact
un peu moi quand même
pour moi c'est vraiment
une suite
la CI pour faire de la qualité du code
et puis la CD pour déployer
ou pour tenir un livrable
et pour moi je le vois vraiment dans une continuité
et pas forcément
comme deux choses séparées
alors en effet il y en a un qui déclenche l'autre
mais pour moi une suite
si je vous laisse sur ta question
pourquoi est-ce qu'on fait de la CI
et pour moi pourquoi on en fait c'est vraiment pour assurer
la qualité du code, que ce soit le code
des applications
ou le code de nos infras
parce que j'imagine que tout autour de la table
on fait des tests de code infras
oui bien sûr on en fait tout le temps
je plaisante
c'est comme on en fait quand on arrive à refaire
la réponse que j'avais de cette question c'était pour gagner en confiance dans le code
mais ça rejoint un peu la qualité en fait
c'est exactement les mots voilà que je voulais entendre
enfin en mon avis c'est
qualité et confiance
qui sont pour moi en fait les étapes importantes du
pourquoi en fait de la CI et pourquoi
en tout cas historiquement on les a fait
et peut-être justement c'est ça en fait le lien
toi Christophe tu parles donc d'une
suite logique entre les deux étapes
je pense
enfin ça allait aussi en partie c'est que la CI
nous donne assez de confiance
pour pouvoir après déployer ce reignement
je pense c'est pour ça qu'il y a
forcément un lien entre les deux
entre les deux qui est
assez logique en fait
après comment tu fais le lien
est-ce que tu correlles les deux
ce que tu les décorais le bon ça je pense que c'est
libre arbitre
moi je disais au début que justement ça peut
être deux process qui vont être asynchro
pour dire tu continues à chipper et ensuite
tu déploies mais qui en effet tous les deux
doit être liés en tout cas
être conscient de l'un de l'autre
moi c'est avec le temps
en fait que je me dis que ça doit être deux process
différents puisque dans
une de mes expériences on avait vraiment essayé
de faire des pipeline
en mode s'époucher s'ébuller s'éployer
ultra linéaire et bloquant
et on s'était rendu compte
en mode donné que justement on avait
des bugs qu'on avait eu du mal à résoudre
ou peut-être c'était les UI
qui étaient mal faits mais on avait avec un pipeline
dont l'historique nous donnait que
le déploiement jusqu'en dev et on avait
plus jamais le reste pour aller jusqu'en prod et on
savait plus du tout quel état était la prod
ou pas et quand t'es à plusieurs ça devient
vraiment compliqué si jamais
j'essaye peut-être de consolider les deux et vous me direz
votre avis c'est que je pense aussi
dans si aille donc comme on a intégration
il y a la manière d'intégrer
comment notre logiciel s'intègre avec le reste
de l'écosystème donc en fait la si aille
inclut je pense
forcément une partie déploiement
et c'est peut-être ça en fait
la chose de ce c'est qu'en fait si jamais on veut
tester par exemple l'intégration avec une base
RDS par exemple notre logiciel il pourra très bien
marcher avec le SQLite local
comment maintenant il marche avec le RDS
distant si je veux faire des tests de bench
moi ma confiance donc on parlait tout à
l'heure de confiance et de qualité
j'ai envie par exemple d'avoir une qualité
en termes de benchmarking de mon code
est-ce que j'ai une régression
sur ça donc forcément
il faut que j'arrive à un moment à déployer
mon code et en espérant pour avoir
la qualité la plus proche et pour faire les tests
qui sont pertinents être le plus proche
possible de la vraie infra
je sais pas si vous me suivez
là dessus en fait je suis assez d'accord
là dessus le problème
c'est que c'est pas toujours possible
et moi je suis typiquement dans un cas
où on a des contraintes de sécurité
très fortes et de séparation
des pouvoirs entre
des personnes qui auraient accès
à des environnements et pas d'autres
et ce closonnement nous oblige
au final à être répercuté
techniquement alors c'est assez
contraire au principe de DevOps
de couper les cloisons
et d'éviter les silotages
mais quand on intègre
un groupe qui a déjà une certaine
détail en fait on peut pas forcément
réorganiser comme on veut et à partir
de là moi j'ai vraiment une séparation
très forte entre la CI et la CD
c'est pour ça qu'on parle de, sur ça
que ma définition c'était livré un paquage
déployable, il y a vraiment une notion
de c'est un contrat d'API
entre différentes équipes
ils livrent quelque chose à une autre équipe
et j'avoue que c'est pas idéal
mais parfois on n'a pas le choix
et pour moi
dans le cas optimal d'une vraie
CI et CD qui fonctionnent effectivement
ça fait partie de l'intégration d'avoir
l'environnement de dev déployer
à chaque comite pour que le développeur
s'aperçoive si ça fonctionne
avec l'environnement complet c'est-à-dire
avec les bases de données, le SSO
et ainsi de suite.
Est-ce que ça rejoint un peu ce que tu disais, Christophe ?
Je vais intervenir, je suis assez d'accord
en fonction des clients
moi j'ai un groupe
qui ont très gros délicits de plus de 2,5 personnes
et en fait la livraison continue
sur notre environnement de dev
et alors
le déploiement continue c'est moi du coup
la livraison en effet c'est de mettre à disposition
le package qui va être déployé
et la décie de ce qui va là
il y a des gros silos énormes
et ils prennent notre package
et ils essaient de l'installer tant bien que mal
je sais pas comment d'ailleurs
avec leur Jenkins
j'ai pas sûr que tu es envie de savoir
j'ai un autre client qui lui carrément va l'excercer
à l'avertis, il déploie à chaque feature
et puisqu'il y a un cluster open shift
à chaque feature il déploie
l'intégralité de l'application
dans un espace séparé
avec tout ce qui va bien
d'accord
qu'on avait vraiment les deux cas
et dans le cas où
tu as un silo énorme entre les deux côtés
comment c'est fait la définition du package
du livrable
à quel moment il y a eu
une définition ou est-ce qu'il y en a pas eu
et juste à laisser faite
justement il y en a pas eu
et donc là
pour le coup la définition du livrable
pour cette DSi
on utilise aussi Open Shift chez eux
et la grande app c'est
les G-Zone qui est extrait
de la
plateforme que nous on expatre
nous l'équipe projet
d'accord et là
c'est clairement un manque de définition
entre nous l'équipe projet
et la DSi
d'accord
j'ai l'impression qu'on a tous au final de part nos expériences
et notre véhicule des définitions un peu différentes
et c'est pas un problème
je pense juste que ce qui est important
c'est que dans l'environnement dans lequel on travaille
c'est de se mettre d'accord
sur la définition entre les gens
qui partagent le même environnement
et puis voilà
et puis ça fait le taf
et donc on a un peu parlé CD
et c'est un
votre manière de le faire
vous allez le faire comme de la CIA
ça veut dire que c'est un script exec qui va se faire un moment
enfin en fait là on a parlé
de pipeline on a parlé de livrable
concrètement
si jamais demain je vais faire la cd
je le fais comment ?
c'est un script exec deploy.sh
à la fin
on a eu une réflexion
intéressante il y a quelques mois
avec des collègues là dessus
du coup en fait on a essayé un peu de redéfinir
notre propre rôle
et du coup en fait plutôt que
s'appeler l'équipe DevOps
ou SRE on a proposé
de se développer développeur d'infra
et je pense que ça résume assez bien ce point
en fait c'est de se dire qu'on est développeur
donc on écrit du code
ça fait le lien tout de suite avec la notion d'infra à scode
ce qu'on écrit c'est de l'infrastructure
et c'est du code source
qui se déploie avec
ce qui se rapprochera le plus
de l'intégration continue
sauf que comme on écrit de l'infra
en fait nous c'est un déploiement qu'on écrit
et
moi parfois j'ai l'impression que notre cd
c'est un peu la même chose qu'une ciay
c'est juste que c'est la ciay du côté infra
c'est une définition
un petit peu
c'est une réflexion qu'on avait eu
le temps d'un déjeuner, ça vaut ce que ça vaut
mais je pense que la notion de développeur d'infra
c'est une notion qui reste chez nous
là depuis plusieurs mois qu'on aime bien
après le lien avec la cd
ça reste à voir
et moi pour moi
c'est un peu ça le but
de la cd c'est de déployer le code
que nous on a écrit dans la phase
de développement de l'infra
et toi
justement tu me disais un peu en off
Christophe que c'était ce que tu faisais
la plupart du temps la cd pour tes clients
toi justement tu vas
préconiser comment est-ce que tu t'adaptes
vraiment au type de contexte
ou est-ce qu'il y a une façon de faire
qui marche mieux que les autres en tout cas pour faire de la cd
non je vais d'abord au contexte parce que
en fait ça peut être soit
je suis assez fan d'ancien
soit je développe des paybooks en cd
qui vont déployer l'application
sur un serveur
mais depuis quelques années je suis très
golden image, infrastructure innuable
du coup
je repacquette spériment le serveur
à chaque nouvelle version
et puis je balance
le logiciel de serveur et je up les nouveaux serveurs
voire
je confie
des containers de coeur
puisque vos panchifs ne peuvent rien
planétiser mais du coup on peut oblider à la voler
d'accord alors là t'as mis
pas mal de la tue d'affaire historique
dans ça le coup
en fait le passage
entre l'infrastructure mutable avec de l'infrastructure
à Scot type
en tibol et après le passage
à du packer et des images
de VM ou de bare metal
d'ailleurs possible
de su
enfin en final là on a 3 processus
en partant après sur les containers
on a 3 processus de déploiement
qui sont vraiment
très très très très différents pour le coup
entre les techniques
à chaque client
ou chaque besoin on adote le processus
et vous dans vos expériences
moi j'ai un peu les mêmes expériences
j'ai connu du
du déploiement
en un synchrone avec
des trucs type chef
donc t'as pas forcément la main dessus
tu sais pas
exactement quand ça va être déployé mais tu sais que ça va se déployer
du déploiement
en pipeline linéaire
avec intégration
déploiement etc etc
en pré-prod et si ça passe pas la pré-prod tu passes pas en prod
tu passes pas en prod etc
et tu es bloqué pour tout le reste
et puis des trucs
des trucs plus
comment je pourrais dire
déploiement
avec des containers de hoqueurs
sur du cumulantisme
maintenant
et selon vous ça va être quoi cette différence
entre les deux ?
pourquoi on a changé le pipeline
au final ?
il marchait
j'ai dans mon étape de ciaï
un truc déploiement
c'est déployé en production
il y a un mot qui n'est pas encore arrivé
jusque là dans notre discussion
et il y en a un très important
en avis, sécurité
dans le pipeline
déploiement
ce qu'on a dit au début
les plateformes type Jenkins
c'est des gros runneurs de script
si déployer c'est un déployer.sh
avec quelque chose qui fait
ça veut dire qu'en gros j'ai un endroit avec une web UI
qui a les droits
d'exec n'importe quoi sur mes comptes au serveur
c'est globalement ça si jamais j'ai résumé
ça ouais
en quoi c'est un problème ?
c'est une question suivante ?
c'est peut-être pour contextualiser
peut-être un peu plus la raison
du pourquoi on a fait
c'est qu'on déploie plutôt un conteneur maintenant
que un...
je pense que ça fait partie effectivement de l'équation
de pourquoi on a changé le mode de déploiement
il y a un aspect sécurité
ça me paraît évident
maintenant que t'en parles en tout cas
pour moi
l'aspect qui m'a le plus sévi
par les histoires de conteneurs et autres
c'est que des outils comme Ansible
ou Ansible
ou d'autres comme Chef
ou Pepet ou c'est plutôt client based
l'un des problèmes que je vois
avec ces outils-là
avec l'avènement des conteneurs c'est que
ça pouvait tout faire
le café, le thé et même le cappuccino
c'est à dire que très souvent
moi je me retrouve avec des exemples où
il y avait une partie c'était configuration de la couche base
commune genre l'OS
sur lequel devait tourner ton application
puis d'un coup on te mettait le template de l'app
de fichier de conf
parce qu'on disait c'est comme ça la config c'est dans Pepet
et puis d'un coup on disait bah tiens ça va aussi faire
des déploiements des trucs comme ça
et du coup c'était toujours
des allées et retours entre
ah tiens faut changer les trucs que t'es config
mais un jeune, puis faut changer les trucs que t'es app
et en fait t'avais des workflows et des cycles
qui n'étaient pas synchronisés alors qu'ils en avaient le besoin
et moi ce que j'ai vu
enfin en tout cas ce qui m'a plu avec les conteneurs
c'est que d'un coup tu repasquettes
j'ai vraiment tout ce dont ton application est besoin
très tôt et pas tellement
ça y est j'ai tout maintenant j'ai plus que besoin
de déployer ou de templateiser ma conf
en fonction de mon environnement et de faire un run
et c'est terminé quoi et t'as plus
ce mélange qui était très
flou entre la partie
run opérationnel qui était au début
préservé par les ops
qui était dans du Pepet versus ce dont ton application
avait besoin qui était ton code base à toi
l'exemple typique de ce type de problème
c'est quand la base
te met un jour le Java et que le jar
que t'installe est plus compatible
c'est pour contextualiser
peut-être pour ceux qui
soit on ne connaît que les conteneurs
soit pour voir les problèmes pour ceux qui les utilisent
et c'est vrai que les conteneurs
résolvent en partie ce type de problème
ça suit l'environnement aussi
voilà et
peut-être la différence
dans tout le cycle que tu nous as dit
un peu Christophe qui était
un de si beul
puis faire des images immutables
de VM puis des conteneurs
dans le conteneur
je pense là on parle tous dockers
je sais que j'ai utilisé des conteneurs depuis un petit moment
mais bon là quand on parle de conteneurs on va parler de dockers
ce qui vient aussi c'est avec une méthode pour les chercher
le docker hub
le docker pass avec le docker hub
et le nom des images dans lesquelles il y a la registrie intégrée etc
au final aussi la différence
c'est ce que apporter dockers maintenant
c'est que ça apportait le format de run
le format d'accès
ça apportait énormément de choses d'un seul coup
en fait
il est fort
c'est devenu un standard de facto
de part l'utilisation
de part l'utilisation par un peu tout le monde maintenant
c'est devenu un vrai standard
qui n'a même pas essayé de s'imposer tout seul
et s'est imposé en tant que tel
mais c'est parce que justement ils ont bien pris le temps
de définir ce contrat d'interface
qui était la cli pendant très très longtemps
docker run
docker build
docker network ce que tu veux
alors qu'en effet le concept des conteneurs
ça n'exétait plus très longtemps
mais la dernière connaissance
que j'avais des conteneurs avant dockers
c'était fait ton image à base d'un débian
que tu sais pas où
ou tu fais un débouze trap quelque part
ensuite un gros targe z que tu mets sur un espèce de serveur
et tu sais pas trop comment le partager
alors qu'ils ont tout de suite mis
les concepts de
t'as un ripot, t'as des tags, t'as des versions
voilà le formalisme pour le build
enfin ils ont en fait mis du formalisme
là où il n'y en avait pas
et c'est ça qui a tout révolutionné en fait
ce que je trouve drôle aussi
c'est que là dans les discussions
on a vu que, enfin vous en parlez comme s'il y avait vraiment
quelque chose de linéaire
entre on va
installer sur les serveurs avec par exemple un plan de cible
puis ensuite on ferait de l'archez immutable
puis ensuite du conteneur
et en fait, bah enfin c'est super chouette
mais par exemple là où je suis actuellement
il n'y a pas de Kubernetes
donc faire tourner du docker c'est bien
mais il y a un OS en dessous
donc il faut aussi qu'on le manage
et donc nous on est toujours sur cette notion
on pousse en fait, on pousse très fort
pour qu'on continue d'utiliser autour de nous
c'est un frais immutable
et on a du mal d'éduquer
les autres personnes qui déploient autour de nous
parce que de leur point de vue
c'est une perte de temps de reforger
une image complète pour avoir une golden image
alors qu'il suffirait
de se connecter dessus en ssh
et moi je sais que le passage de l'un à l'autre
en fait, nous on le justifie
parce que bah on a beaucoup moins d'erreurs
que tous les projets qu'ils le font
en mode on se connecte en ssh
et on fait les mises à jour
mais ça reste un message qui a du mal à passer
et je sais pas si
vous avez gênant de trucs mais...
Moi je voudrais répondre avec par rapport au golden image
en effet,
j'ai fait un temps
je pratiquais aussi la construction
d'Ai-Mai pour Amazon
les Amazon Machine Image
et ça en effet ça prend beaucoup de temps
parce que chaque fois c'est un blob entier
et là où encore une fois Docker ils ont réfléchi
à la problématique
et ils ont apporté une solution
qui était le concept de layers
ce qui te permettait également de gagner énormément de temps
quand tu le faisais de manière intelligente
quand tu savais redonner
tes sources et ok ça c'est un fichier
qui va changer très souvent je le mets à la fin
ça c'est un truc qui ne change pas je le mets tout au début
et avec télétr
du coup même rebuil d'animages
qui sera un livrable entier en fait
ça permettait d'être rapide
Un point peut-être qui peut être une
explication ou en tout cas
une solution pour convaincre
à passer à l'imitable
c'est dans le cas où on commence à avoir beaucoup
de services différents sur une même machine
parce qu'en fait
on a des petits services
qu'on va appeler
micro services
et donc
quel va être justement ce contexte là ?
est-ce que vous pensez pas que les micro services
ont justement un impact
sur la manière dont on déploie et l'entend cas ?
si bien sûr parce que les micro services
au final ça va être des équipes différentes qui vont le développer
qui vont les développer
qui seront probablement pas écrit
enfin peut-être pas écrit dans le même langage
qui auront pas été
billé de la même façon
qui auront pas les mêmes dépendances systèmes
qui auront pas besoin des mêmes librairies etc
et ça
quand tu veux faire ça sur un OS standard
installer les milliards de dépendances
dont tu vas avoir besoin pour faire tourner ton code
avant que ce soit des binières
compilées
mais si ce n'est pas le cas tu veux juste
galérer à fond et probablement
tu vas avoir des conflits etc et ça va être juste un enfer à gérer
et avoir un truc où tu déploies
des toutes
et micro services
qui sont buildés
avec un artefact docker
et donc du coup
du point de vue
du point de vue du système sur lequel tu vas
aller faire tourner au final
ce sera juste la même chose
pardon
c'est beaucoup plus simple en fait
du point de vue du système sur lequel tu vas déployer tes artefacts
ce sera un seul type d'artefact
et non pas 15 différents
et toi Christophe est ce que tu as eu
une expérience comme ça avec les micro services
est ce que tu as plutôt l'habitude de déployer
des micro services ? Est ce que ça va changer
pour toi la façon de faire ?
un petit peu oui quand même
parce que du coup ça doit être à chaque micro service
et voir aussi les dépendances
entre les services parce que c'est bien beau
de déployer un service parmi
une filetée mais si il y a
des dépendances qu'il faut gérer en plus
le procès de déploiement est plus très facile
en fait
j'admette justement il y a des micro services
et sa philosophie a été
quitte à déployer le micro service
on va redéployer intégralement
la stack
complète en blue green
et même si il y a qu'un seul service
qui change on va tout déployer
sauf évidemment la base de données
là il y a en dehors du cluster qu'il y a pas de problème
c'est assez marrant c'est qu'en fait
les micro services reviennent aussi
à la problématique de CIA
et en fait là c'est un peu ce que tu dis
non ? un petit peu
parce que du coup en effet
on déploie à côté et on peut regarder ce qui se passe
c'est cette notion
d'intégration en fait
dont on parlait tout à l'heure
j'avais résumé en parlant d'une base de données rds
ou quoi que ce soit mais en fait
quand on a un micro service
l'extérieur c'est
nous-même en fait
et je trouve ça assez marrant
le reliant
que la CIA impose
et d'ailleurs toi Christophe
tu vas le faire comment ? tu disais que tu déploie
entièrement toute la stack à chaque fois
pour pouvoir tester ?
non ça dépend des projets
là c'est l'exemple d'un client qui va vraiment très très loin
non
je sourde pas le
micro service mais j'ai pas beaucoup de micro service
chez mes clients
et quand il y en a
il y a assez peu de micro service pour l'instant
j'ai des petits clients
sur le gros là
mais pour le coup pour lui
c'est plus une seule application donc le micro service c'est le seul
donc
je le déploie je le bile
et puis je le recharge
et il prend la main sur l'ancien
dans ces images
d'accord et alors pour vous
qu'est ce que vous verriez comme solution
justement pour pouvoir tester
là un peu déployer une stack ça peut se faire
si jamais on est un Uber par exemple
si quelqu'un fait un comitre
je vais peut-être pas redéployer 7000 services
d'un seul coup
vous feriez comment
par exemple pour pouvoir tester ça
quels sont des pratiques
que vous pourriez mettre en place
en fait c'est en gros
enfin là ce que je suis en train de
aller je dis la solution
d'arrêter de tiser comme ça
toute la notion de stub de moq
notamment qu'on va avoir
en fait pour pouvoir
tester un micro service
ce qu'on va essayer de faire c'est de l'isoler par rapport au reste du monde
et se dire il a des entrants
et des sortants bon bah je fais
des faux entrants et je fais des faux
des faux entrants et des faux sortants
qui sont en fait la définition
du contrat qu'on s'est fixé
avec le reste du monde
et ça comment vous le feriez
si jamais
quelque chose d'assez amusant moi dans le cas
qui s'est présenté là il y a pas très longtemps
c'est que l'équipe de développement
n'a même pas accès à l'environnement de qualification
ils sont accès à un environnement de qualification
qui est chez eux mais qui est à l'extérieur
de l'entreprise
et dans ce cas là
en fait s'ils ne moquent pas
les services de l'entreprise
ils y ont juste pas accès en fait
donc là en fait
c'est assez drôle parce que c'est complètement
hors
d'evobs et philosophie d'evobs
on leur a filé des documents
quand je dis on c'est pas mon équipe je suis pas responsable
ils ont reçu des documents
ou Word ou des PDF
qui expliquaient les contrats d'API
de ces services qui étaient en interne
qu'ils ne pouvaient pas accéder
ils ont donc développé en aveugle
avec des moques
et quand c'est arrivé en qualification
ils se sont aperçu que ça ne marchait pas
et moi j'ai trouvé ça très drôle en fait
c'est de développer avec un document PDF
qui n'est pas à jour
à l'aveugle donc on fait des moques
et on gagne en confiance sur le code
parce que les tests passent et parce que
tous les moques sont bons
sauf qu'ils ne correspondent pas à la réalité
et voilà c'était une anecdote marrante
j'ai trouvé ça très drôle quand j'ai découvert
c'était moins drôle d'un point de vue projet
parce qu'on a quand même pris un mois de retard à cause de ça
mais voilà c'était l'expérience que je voulais partager
autour du moque
non en fait
en vrai ça c'est marrant parce que tu as vécu
le pire du définition de services
mais là je pense que vous n'avez pas eu de retour
rapide dessus
ce qu'on essaye peut-être de faire pour résoudre
ton problème c'est on définit un contrat
on essaie de s'y tenir
mais surtout on essaie de le tester
je sais pas où est-ce que t'es le problème de ton problème
en fait le problème il est que
les équipes sont
d'entreprises différentes
et dans des bâtiments, des villes différentes
et donc quand on n'a pas une bonne culture
du travail en remote et une bonne culture
du partage
ça passe mal en fait tout simplement
c'est à dire qu'il y a des solutions
qui existent, il y a des
instances de tests qui auraient pu être mis
à disposition de cette équipe externe
ça n'a pas été fait
juste par des contraintes
de temps et de mauvaise communication
en fait les problèmes
sont pas irrésolvables, c'est même pas
des problèmes techniques là pour le coup
c'est vraiment qu'un problème d'organisation
quand l'organisation devient trop grosse
les contacts humains sont plus difficiles
et ça ralentit
ça ralentit énormément
et moi j'ai pas vraiment de solution
je travaille énormément là dessus
c'est aussi pour ça que j'aime beaucoup ma mission actuelle
c'est justement de, je m'intéresse
assez dynamique en fait
comment on en arrive à ce genre de situation
qui sont assez ubuesques, qui nous font perdre
au final beaucoup de temps
alors qu'en fait on avait tout ce qu'il fallait pour réussir
on avait même toute la bonne volonté du monde
en fait il n'y avait pas spécialement de mauvais profils
qui faisaient n'importe quoi
c'est simplement qu'on n'a pas réussi
à se mettre d'accord suffisamment vite
et bah voilà j'ai pas vraiment
de solution, je trouve que l'anecdote est marrante
parce que après coup c'est comique
après c'est vrai que sur le coup
ça nous a pas vraiment fait rire
c'est euh...
oui fin tu...
tu vis à athlète avec eux le pire
du pire de ce qu'on avait
avant dans la sémission
d'un KD Charm en fait
et la bonne game est à l'envers
ça a l'air horrible, des profils comme nous
qui bougent beaucoup, qui allons dans des boîtes
qui ont différentes tailles et qui essayent des nouvelles pratiques
mais je suis absolument
sûr et certain que c'est le standard
d'encore beaucoup d'endroits et dans beaucoup de grands groupes
euh... je pense pas qu'il faille négliger
ce genre d'environnement
à mon avis qu'il y a encore beaucoup d'entreprises
qui fonctionnent de manière très silottée
et qui ont ce genre de problèmes de communication
et c'est aussi pour ça que ça m'intéresse beaucoup
j'ai vraiment l'impression
que l'expertise humaine
de comprendre ces dynamiques
et essayer de... d'y remédier
c'est une compétence à part entière de nos jours
euh...
en tout cas dans le domaine
dans le domaine de DevOps au sens large donc on essaye de casser les silos
bah il faut comprendre les silos
pour pouvoir les casser en fait
tu veux... oui je pense on est...
bon je pense on est d'accord
moi il y avait un point
il y avait un point qui m'intéressait aussi
c'est
jusqu'où vous avez confiance
dans votre CIAI
on a parlé de confiance, on a parlé de qualité
jusqu'où vous seriez capable
d'aller
d'aller
en...
en confiance
en fait
c'est vraiment votre CIAI donc on a dit
on augmente la qualité, on augmente la confiance
vous êtes allés jusqu'où maintenant
est-ce que vous seriez capable de laisser
je sais pas
le logiciel de votre voiture vous conduire
parce qu'il y a une CIAI qui a passé tous les tests
pourquoi pas
il y a pas Tesla qui le fait déjà
pas vraiment, c'est automatisé
de tout et ça te laisse
mais justement à votre avis
jusqu'où on peut aller dans la confiance
de la CIAI, est-ce qu'il doit y avoir
une étape manuelle à un moment ou un autre
est-ce qu'il doit y avoir
est-ce que vous seriez
capable de laisser vraiment
genre quelqu'un comite
si ça passe les tests, ça passe en prod
pourquoi pas
je pense qu'il y a une certaine notion de maturité
à voir, j'imagine que
j'aurais plus confiance dans la CIAI de Amazon
que dans celle que j'ai mise en place
parce qu'on l'a mise en place à la rage
alors détrongue-toi pour le coup
vu l'article sur les tools
internet tools de Amazon
mais quand quelqu'un arrive à comiter chez Amazon
il a un t-shirt
parce qu'il met tellement de temps et c'est tellement compliqué
que si il arrive à comiter il a un t-shirt
moi j'imagine qu'ils étaient un peu à l'état de l'art
de ce qu'ils se faisaient mais je travaille pas
chez Amazon
quand je parlais de vidéo ce n'était pas Amazon
non non c'est tout le paradoxe
Amazon en interne
mais on n'est pas du tout
pour plein de raisons qu'on a vu
de nous dans d'autres sociétés
mais bon, si vous voulez
on mettra le lien en description
à un moment
pour répondre à la question
pour moi c'est un petit peu le même calcul
que pourquoi je fais confiance à un avion de ligne
c'est une question de statistique
je pense que je rentrerai pas
dans un 737 MAX
de chez Boeing
mais de tous les autres avions
typiquement si je prends une compagnie
validée en France je suis à peu près sûr
d'arriver à destination
pour la CIA c'est un peu pareil
si la CIA fonctionne tellement bien
que les devs vont même oublier l'URL
et qu'il la regarde de plus
c'est que ça fonctionne vraiment très bien
après j'ai un ancien collègue
qui me disait très justement
une CIA qui est toujours verte elle sert à rien
et quelque part c'est pas forcément faux
c'est à dire que ça sert aussi au devs
à retrouver leurs erreurs
donc il faut qu'ils aient l'info
de quand eux font une erreur
et c'est justement la CIA qui fonctionne bien
à partir du moment où il n'y a que les devs
qui reçoivent ces erreurs
Et toi Christophe
ça va être quoi le niveau de confiance
que tu vas pouvoir atteindre dans la CIA
Moi mon niveau de confiance
il y a beaucoup de tests
et si il passe je peux avoir confiance
jusqu'à des feuilles automatiquement
en mode
après les questions
que tu soulèves
sur est-ce qu'on peut faire confiance
à une voiture autonome
ou autre pour moi c'est plus avant la question de confiance
et là on se rend un peu de la technique
pour moi c'est des questions d'hybrarbitre
est-ce que je vais laisser quelqu'un
conduire ma voiture
enfin quelqu'un quelque chose
en l'occurrence conduire ma voiture
est-ce que je laisse ça
à un robot
est-ce que je fais confiance à l'expérience
d'un animal qui ne peut pas être
sur le piste par un robot
et là je crois qu'on sort vraiment
du champ de la CIA pour moi
Non mais c'est un bon
c'est une bonne question en fait que tu poses
parce que moi je me souviens
typiquement que
dans certains cas le déploiement
il y avait des gens qui me disaient non mais on a appris
dans les déploiements et jamais une machine
ne pourra avoir notre expérience
qu'on a eu sur les déploiements
seul le développeur peut
déployer ou seul l'administrice
peut déployer parce qu'il connaît les contraintes
générales du projet
et aucune personne pourra la voir
c'est quelque chose justement enfin j'ai souvenir
de certaines discussions chez certains de mes clients
mais je parle de ça en 2011-2012
enfin ou 2010-2011
qui était un peu sur la même chose
après là je dis pas que c'est le cas pour la conduite
et peut-être la différence qu'on fait
là c'est la notion de mort et de vie
mais si jamais on le fait dans le cas
des déploiements c'est
si jamais le déploiement se voit potentiellement
il y a des gens qui sont virés aussi
on pourrait très bien voir qu'un logiciel
qui part en vrille et qui commence
à liquer
tout sur internet etc etc
ou plein de choses on peut très bien avoir
des gens qui sont virés pour ça
Exactement je pense que ce que tu soulèves là c'est la notion de risque
et si le risque est trop important
est-ce qu'on laisse la C.I.
et la C.D. se dérouler jusqu'au bout
ou est-ce qu'on la pose
on regarde ce qui va se passer
et est-ce qu'on la lâche
et pour moi cette notion de risque
est de risque
c'est stable c'est tout de savoir
si on le compte
Je suis entièrement d'accord
c'est en fait la C.I. et la C.D. sont mises
en face d'un risque
et je redéfinis le risque
parce que très souvent on me parle de risque
et j'en ai marre on le définit mal
c'est pas que l'occurrence d'un problème
c'est sa gravité également
mais aussi sa détectabilité
un problème qu'on ne détecte pas mais qui n'est pas grave
enfin n'a pas d'incidence forte
et tout de même un problème très important
c'est jamais il reste dans le long terme
donc voilà c'est juste un rappel
c'est l'assemblage de ces trois
gravité, occurrence, détectabilité
Dépêle-liens parfaitement
au fait que pour chaque projet
on a, enfin dans la mission actuelle
dans ce gros client
un audit de sécurité systématique
et dans cet audit de sécurité
il y a justement la séparation
des rôles de qui fait le déploiement
qui fait le développement
et du coup
il y a ces questions
en fait de savoir est-ce qu'on laisse
une CIA complètement faire
de bout en bout le déploiement
et en général ça se finit
par en tout cas dans ce contexte
là, à une séparation
de pouvoir donc il faut une validation humaine
à chaque étape
donc il faut qu'un humain lance
le procès de déploiement et il ne pourra pas
être automatisé dans notre cas
et ça en fait
c'est une gestion de risque
tout simplement, c'est le risque
au sens de l'audit de sécurité
donc comme t'as dit c'est
la probabilité que ça arrive
face à la gravité si ça arrive
Et là Christophe
tu me parlais de continuous pen test
Oui
en fait j'ai le même problème chez Zac Lluy-Han
qui reprend
notre projet
avec
un projet qui est repris par la DSC
du client et du coup on passe
d'une égocité de rencontre
un déploiement par jour
à un déploiement toutes les 3 semaines
parce qu'il faut faire des tests
d'intégration
des tests de
des tests d'intrusion
par une société externe achet
ce qu'il faut du coup ça
ça prend longtemps
et c'est là
où justement les tests
les pen test
donc les tests d'intrusion
d'intrusion persillez
les tests d'intrusion en continu
après les paumants peuvent avoir leur importance
parce que si on peut
déployer en continu
rien ne nous a interdit de faire des tests
d'intrusion en continu
et s'il n'y a pas de grosse évolution
majeure du logiciel
il n'y a pas nécessairement besoin
de faire appel à une équipe
ou à un service externe
dans le cas de grosse évolution
ou d'une évolution d'architecture
et ça c'est encore une évolution
un train rail je pense
moi je l'ai encore jamais fait mais c'est quelque chose
que je rêve de faire
je pense que tout ce qui est important
dans tout ça c'est la notion
de risque
qui est au coeur du truc finalement
et qui place le curseur de la confiance
et du lâcher prise on va dire
à quel point
à quel point on autorise
où on permet à la CIA
de faire son boulot tout seul
sans qu'on ait un œil à garder dessus
et un bouton apprécié
pour appuyer
pour que ça parte en prod
et tout ça c'est un calcul à faire
c'est qu'est-ce qu'on est prêt à accepter
qu'est-ce qu'on est prêt à faire
pour que ce risque soit
mesuré et il soit
stable dans le temps on va dire
c'est un
point là c'est que la CIA
elle augmente l'observabilité de notre plateforme
c'est à dire qu'il y a un bug
normalement on le détecte très tôt
dans le développement et donc on aura normalement
un risque moindre
en tout cas on baisse le risque
en augmentant l'observabilité
via la CIA
et donc c'est à quel moment
c'est face à une gravité qui est vraiment gigante
avec du type mort d'être humain
c'est est-ce que vraiment on arrive à monter
l'observabilité de manière assez forte
pour pouvoir baisser quand même la gravité
c'est ça le... et est-ce que lui-même
à un moment... et je sais que j'avais un ami qui bossait
sur les bandes test des moteurs d'avion
et c'était ça en fait
enfin c'était en fait
chaque nouveau logiciel c'était des semaines
de qualification je crois qu'il m'avait dit
c'est écouter 40 000 euros quelque chose comme ça
chaque version a validé
c'est même pas une version poussée en production
c'est vraiment juste une version qui doit être validée
et c'est 40 000 euros à peu près
juste pour la valider
et donc là pour le coup on a une CIA à 40 000 balles
à chaque fois je pense que je la ferai pas à chaque comite
pour le coup
Oui mais c'est sûr c'est vrai
que nous on n'est pas dans ce genre de problématique
donc on ne se rend pas forcément compte
quant à des problématiques comme ça
de prier et de...
de durer extrêmement long de CIA
et on est plutôt dans du logiciel
qui impacte pas trop l'humain
donc on se pose pas ce genre de questions au quotidien
après quand tu es dans ce genre de milieu effectivement
tu te poses peut-être plus la question
tu essaies peut-être de plus rationaliser ton usage
de la CIA
Alors il y a cette solution là
c'est un peu je pense la solution que SpaceX a fait
qui est en fait de réduire la gravité
en permanence des problèmes
tu vois si on prend une entreprise qui envoie des fusées
ils ont eu plein de problèmes, ils ont testé
ils ont résolu au fur et à mesure
ils ont fait juste par apprentissage
et si jamais demain ils ont des humains qui envoient
bah en fait la capsule est capable
d'elle-même de se barrer
et en fait il baisse la gravité
à la différence d'une navette spatiale
quand il y avait un problème, il y avait un problème
tu peux aussi avoir cette notion là
ou quand tu as des envies humaines mises en jeu
qui est bah tu baisse la gravité
de tes...
d'un échec en fait
d'un erreur
Tu l'acceptes mais tu t'apprends le... à le contrôler en tout cas
Exactement, c'est la mitigation de risque en fait
On en revient exactement à cette notion de risque
où tu disais c'est pas que
la gravité c'est... enfin c'est la probabilité
et la gravité en fait, il y a vraiment les deux notions
Oui c'est...
Moi souvent c'est ce que j'ai vu dans mes précédentes expériences
et notamment quand on fait
donc un...
je me souviendrai jamais de ce nom, un feedback après
un post-mortem
ce nom est impossible pour moi à retenir
en tout cas quand on fait un post-mortem
j'ai souvent vu
la problème de l'occurrence
c'est à dire on veut savoir d'où est-ce que ça vient
il faut être résolu et on met un test
en...
en perspective par rapport à ça
mais jamais personne s'est posé la question de sa gravité
genre peut-être que le problème n'aurait pas dû
impacter autant la prod
ou aurait dû être résolu plus vite et aussi
il y a aussi encore un dernier point qui est le temps de résolution
c'est un problème qui arrive mais qui dure un frais-exemple de seconde
et qui n'a pas d'impact sur le reste des choses
c'est un problème mais c'est pas forcément un problème
c'est jamais il est autorémédiais
c'est pas un risque
enfin c'est pas un risque très important
par contre un problème qui n'est pas autorémédiable
là pour le coup devient un problème
je sais pas si je me suis fait comprendre l'indemne
j'ai rajouté même un quatrième critère
au risque la remédiation possible
de ce problème là
et le temps pour y arriver
mais tout à l'heure t'as parlé d'observabilité
je pense que c'est important aussi
si tu veux vraiment pousser la confiance au plus loin
dans tous tes process de CIA et de CD
si tu veux vraiment aller jusqu'au déploiement
continu et automatique de ton application
je pense que c'est important d'avoir une observabilité
au sens large du terme
qui tient la route
et tu peux même pousser le viste encore plus loin
ou si jamais ton truc est déployé
et que t'as tes métriques business
qui sont bien définis et c'est là etc
et c'est lié c'est l'eau tout ça
tu pourras même imaginer
brancher ton truc
dessus, ton process automatique
et si jamais il s'aperçoit
que les métriques qui sont importants
pour toi sont
un partenvry
tu peux rollback
à la version précédente
tu peux imaginer des choses comme ça
ça a l'air tellement bien de bosser avec toi
ça va être bien ?
c'est du rêve
après il y a la réalité malheureusement
c'est le problème
j'ai une solution
il y a une chose qui est possible
qui peut améliorer les problèmes
la solution d'après
qui est le feature flag
le feature flag
il vient parfaitement dans cette discussion
c'est qu'il baisse
la gravité
on a une solution qui n'est
à t'activer que pour
un jeu particulier
d'utilisateurs
je vais activer pour 5% de mes utilisateurs
la nouvelle fonctionnalité
ça c'est une première façon de remédier
un peu le risque d'avoir des tests
donc j'ai que 5% de mes utilisateurs pas contents
si jamais ça marche pas
on a encore un truc
qui est
quand je déploie
ou quand je fais mon code
si jamais la feature flag
est off par défaut
j'ai plus confiance en moi
parce que aucun des tests
passe
mais je suis pas sûre de cette nouvelle fonctionnalité
parce que mes tests
j'ai pas une confiance en eux importante
je vais déployer
avec cette fonctionnalité
et elle va être activable
à la voler par quelqu'un
et on a quelque chose
d'assez sympa
où le test se fait en production
le feature flag c'est vraiment ça
rajouté les deux
tu vas voir que tu auras la fonctionnalité d'activer
mets-toi un flag dans la base de données
tu verras, tu vas devenir
tu vas activer telle autre fonctionnalité etc
et c'est quelque chose que je vois trop peu utilisé
à l'heure actuelle
je vois dans Chrome
qui adore les features flag
et je trouve ça vraiment génial
dans plein d'autres choses
Google en utilise en voûtu
et c'est quelque chose que je vois pas assez utilisé
dans les CI
et ce côté un peu
en fait je pense que ça enlève le côté
genre je merge
et je prie que mes tests soient bons
quelque chose où tant que je ne l'ai pas déployé
en prod je ne sais pas si mes tests sont les bons tests
alors que là on pourrait très bien avoir
quelque chose où si jamais moi j'active le flag
ça fait sauter le serveur
oui mais je suis tout seul donc ça fait sauter
sur une requête et ça fait sauter un serveur
on peut imaginer que le système en dessous a fait du recovery
dessus mais j'étais tout seul
à faire sauter le serveur en production
et c'est assez peu utilisé
malheureusement et ça peut enlever
l'espèce de pression qu'on garde encore
sur la confiance dans nos tests
en...
je sais pas ce que vous en dites
je suis d'accord avec ça et c'est marrant que t'en plait
parce qu'on est exactement en train de mettre ça en place
dans ma boîte justement
il y a un truc de feature flag pour pouvoir pousser des trucs
et les activer à la volée
à activer ou désactiver à la volée
oui je dois avouer qu'on a un retour d'expérience
similaire et c'est vraiment très agréable
moi le seul problème que j'ai avec ça
c'est qu'on fait tous les efforts possibles
pour pousser de l'infra immutable
et le feature flag dans ce cas-là
il fallait se connecter en assez sages
mais c'est du... voilà
c'est pour pignoler parce que vraiment
ils l'ont fait propre, c'est vraiment une commande
à lancer
ça se passe plutôt bien mais
voilà c'était la seule critique que j'avais là-dessus
après quand je les proposais à d'autres projets
la réponse qu'on fait régulièrement c'est le
oui mais il faut demander d'un truc
au dev et donc ça coûte cher
mais bon ça après c'est aussi
des questions ça dépend du client quoi
c'est ton contexte là pour le coût qui règle
enfin qui fixe un peu le besoin
voilà c'est un contexte particulier
où les équipes de dev sont souvent externes
et avec des équipes externes
un développement supplémentaire ça se traduit
en un devi supplémentaire
donc...
donc la question n'est pas que technique
et ça complexifie beaucoup les choses
quand les questions ne sont pas que techniques
mais je pense qu'on est tous d'accord là-dessus
tu veux dire humaine et financière
ouais entre autres
en fait je connais que ça mais ouais
euh... Christophe
tu avais d'autres exemples
pour le feature flag moi je me demande
aussi pourquoi c'est pas aussi répandu
je me montre si c'est pas un coût développement supplémentaire
pour les devs
si ça leur demande pas beaucoup plus de travail
et je pose aussi la question du
le coût en tant machine est-ce qu'il a
un impact sur l'observibilité
ce qu'on peut faire aussi c'est au moment
où on déploie on peut notifier
ces serveurs de supervision
déclencher un événement et comme ça
si il y a des alertes sur
sur la utilisation de CPU, sur la tradition des moires
etc on peut voir si ça a un impact
direct, direct, lié au déploiement qu'on vient de faire
par règle
donc en fait c'est quelque chose de post-héritier
on a au moins la visibilité de
ce qu'on a fait
ça c'est intéressant ça te paraît de faire de la corrélation
d'événement c'est genre je sais que j'ai déployé
à tel moment et j'ai des problèmes
pardon je sais que j'ai déployé
à tel moment et je sais que j'ai commencé
à avoir des problèmes juste après donc peut-être que
en fait c'est mon déploiement qui a tout fait foire
et quoi
je pense qu'on a pas mal évoqué
tous ces sujets là
je sais pas si ça vous va
là dessus, est-ce que vous avez quelque chose d'autre
d'ultra important que vous n'avez pas dit
et là qui vous revient
magiquement en tête
si moi j'ai un truc qui me vient en tête
c'est
un retour d'expérience après avec l'usage de Travis
et ce genre d'outil qui peut
être mis à disposition
c'est que de temps en temps d'autre je suis arrivé
à l'état où l'image
le builder Travis
était trop pimpé
par le service de delivery
c'est à dire qu'il me fournissait des outils que
des fois les développeurs
supposés qu'ils étaient là et leur existance
on me doit pas de problème
ça c'est un FPM s'installer
le docker compose s'installer dans telle ou telle version
et du coup
toutes les commandes qu'il y avait dans le Travis Yamel
ils étaient incapables d'exécuter la même chose
sur leur poste donc par exemple
t'invites ton Travis qui te sortait une erreur
et t'es là en mode ok super
la CIA me dit que ça marche pas mais j'ai aucun moyen
de pouvoir reproduire le problème chez moi
et donc l'un de mes
mes toutes premières actions
et toutes premières chantées que j'ai entrepris quand je les ai rejoint
c'est dire non non non il n'y a pas moyen
tout ce que la CIA exécute on est capable de le faire
en local et je vous invite d'ailleurs à le faire
en local avant de pousser sur la CIA
parce que ça aussi c'est un petit effet des fois que je trouve
moins un peu pervers mais il faut pas généraliser
c'est
des gens, des personnes, ils compris
moi en de temps à autre qui ne prennent plus le temps
de tester en local et qui pouchent en fait
je fais une une de code je contrôle je comite
je pouches et j'attends que la CIA elle pleure
parce que je suis incapable de tester en local
et ça c'est un comportement que j'aime pas trop
donc moi maintenant je m'efforce toujours de faire en sorte
que toutes les commandes qui puissent être
dans Travis Yamel pour en gros c'est qu'un
script d'enchaînement de commandes
mais toutes ces commandes là doivent pouvoir être
exécutées sur le poste de développement
et tu fais ça comment ?
je rap absolument tout dans des cantonards
d'Ocker
mais ça m'a sauvé
la vie une ou deux fois parce que justement
ce fameux worker Travis avait
fait un upgrade sur le Gradle
sur le FPM ou sur l'environnement ruby
et c'était eu
et maintenant
ce qu'on a c'est qu'on a un
repository qui est un ce module de tous nos projets
et ce
projet là lui il embarque des wrapeurs
qui disent bah voilà Gradle en fait
c'est Docker Run telle image avec telle volume
qui va bien
l'autre effet assez intéressant qu'on a
c'est que les images en fait on les pine
on n'est pas sur du lay test
et vu que c'est un ce module que tout le monde
met un jour systématiquement quand il fait un guide pool
et bah quand
par exemple moi je mets un jour et je dis maintenant on utilise
telle version de logiciel bah le prochain pool
les devs et forcément tout le monde utilise
la mise à jour de ce logiciel là et ça évite
des fois des problèmes
des fameux pep cac je comprends pas ça marche pas
sur mon poste bah pourtant ça marche sur l'OMI
et en fait c'était une mise à jour d'un outil
que tu dis ce que une fois tout est 36 et qu'était pas
la même version ça a aussi ce côté
là et l'onboarding aussi est ultra rapide maintenant
puisque Docker a aussi le bon goût
de faire un pool automatiquement quand
tu fais un run d'une image qu'il n'a pas
nous on a on a on bordé récemment 5
personnes en une semaine grâce à ça parce que
les mecs ils faisaient un guide pool
un éval d'inscript qui te mettaient ton passe
dans le souris pertoir
puis après ça appelait le wrapeur qui faisait un docker run et ça re-télécharge
les tout à la volée quand ils en avaient besoin
et tout fonctionnait
et là t'avais la promasse de Docker
builditre net everywhere
c'était effectivement un très bon point
non mais c'est
c'était quelque chose tout à l'heure c'est vrai qu'on est parti
dans les travis etc
dans le repository driven
la troisième génération je dirais
donc dans travis
au début c'était du travis.yamel
où on utilisait une box à eux
c'est vrai que maintenant en fait
j'ai cherché un peu des c.i.e.s
mais je n'ai pas de box travis
de box yamel
je vais y arriver de box docker
et ben j'en ai pas trouvé maintenant
ça devient le standard en fait
qu'est-ce qu'il y a
une c.i.e.s c'est des commandes à exécuter
dans un docker
après un guide clone
comme docker a également permis la démocratisation
des microservices
avant c'était tellement chiant
les dépendances pour installer un os
avec toutes les services que tu faisais pas autant de petits services
le fait de pouvoir tout chipper rapidement
ou alors ce qu'on faisait on le faisait dans un seul langage
et donc tu avais au sein de ton langage
un premier dossier avec le projet A
un deuxième dossier avec le projet B
etc et tout le monde partageait
le même runner
c'était notre façon de faire du coupage en service
c'est vrai qu'il y a de plus en plus de services
de c.i.e.s à ce service
et avant travis c'était le premier
et pendant très longtemps c'était le seul
et ensuite grâce à l'avènement des conteneurs
tu as eu drone
maintenant même circle.ci
c'est tout dans les conteneurs
concours c'est tout dans du conteneur
la c.i.e. que dans des conteneurs
c'est tout ça c'est un mot clé
c'est la reproductibilité
que tu cherches à attendre
tu veux que ce côté que tu exécutes sur ton poste
sur n'importe quel c.i.e.s
ce soit toujours la même chose
et au final c'est ça c'est juste des conteneurs
qui auront toujours le même environnement
et non pas un truc que tu auras réinstallé
from scratch à chaque fois avec des versions de
version de libre différentes
et du coup t'es pas sûr que ça va pas créer des effets
de bord etc t'auras toujours exactement
la même chose et c'est ça qui est super important
ok
c'est vrai qu'il y a encore plein d'autres choses
à parler quand on peut parler comme ça de c.i.e.s
tu dis à reproductibilité
il y en a même certains qui essayent d'aller jusqu'au
binaire perfect
faire en sorte que deux runs de c.i.e.s arrivent
au même artefact
au binaire pr... au...
au bit prêt, à l'octet prêt
donc ça c'est encore un truc
je vais pas aller là-dedans mais si jamais vous voulez
vous renseigner là-dessus, commencez à y aller
regardez aussi des systèmes comme Nix
Nix
qui sont pas mal justement pour arriver à ça
je vous tease un peu là-dessus
j'ai pas assez d'expérience
il y a cette expertise là-dessus pour vous aider
on va
on va s'arrêter là
sur le... le vaste
univers des... des c.i.e.s
décidies
je t'en ai d'abord à remercier Christophe
parce que c'était ta première...
avec nous, wood wood
merci, merci à vous
et à distance en plus
ouais voilà donc là on va voir
là pour le son donc désolé
si jamais... désolé si jamais
le son là était pas... était pas parfait
voilà on expérimente
on teste, la gravité est pas trop important
vous voyez on a... on a ségrégé
le problème à un intervenant sur cinq
désolé pour toi mais
tu es notre abe test du jour, merci Christophe
ça fait 20% quand même
bah c'est un gros abe test
et puis merci à tous de nous avoir écoutés
si jamais... donc je pense le mois prochain
en ce cas prochain numéro il sera sans doute
sur Kubernetes
dans un... dans ton cube
si jamais vous voulez participer n'hésitez pas
à venir sur le spectrum, dans les commentaires
YouTube
à venir nous voir en live, n'importe où
on se trouve à la Postcafé, ce que vous voulez
venez nous voir, venez participer
parce que vraiment on veut avoir vos expériences
différentes, vous avez eu des contextes
et... et tout expérience est bon à prendre
pour le coup, vraiment c'est le cas
donc prochain sans doute sur dans ton cube
et puis la fois d'après
encore un DevOps
sur un sujet qu'on définira
donc venez même aussi discuter pour définir
le sujet, ce qui vous intéresserait dont on pourrait parler
ou même ce dont vous voulez parler directement
voilà
et bien merci à tous, merci le live
les gens qui nous ont suivi
et puis... et puis à une prochaine
salut bientôt, tchoo tchoo
Episode suivant:
 Dev'Obs #14 / Kubernetes, révolution ou buzz marketing ?
Dev'Obs #14 / Kubernetes, révolution ou buzz marketing ?
Les infos glanées
DevObs
Dev'Obs Le magazine et observatoire du DevOps
Tags
Card title
[{'term': 'Technology', 'label': None, 'scheme': 'http://www.itunes.com/'}, {'term': 'News', 'label': None, 'scheme': 'http://www.itunes.com/'}, {'term': 'Tech News', 'label': None, 'scheme': 'http://www.itunes.com/'}, {'term': 'devops', 'label': None, 'scheme': 'http://www.itunes.com/'}]
Go somewhere